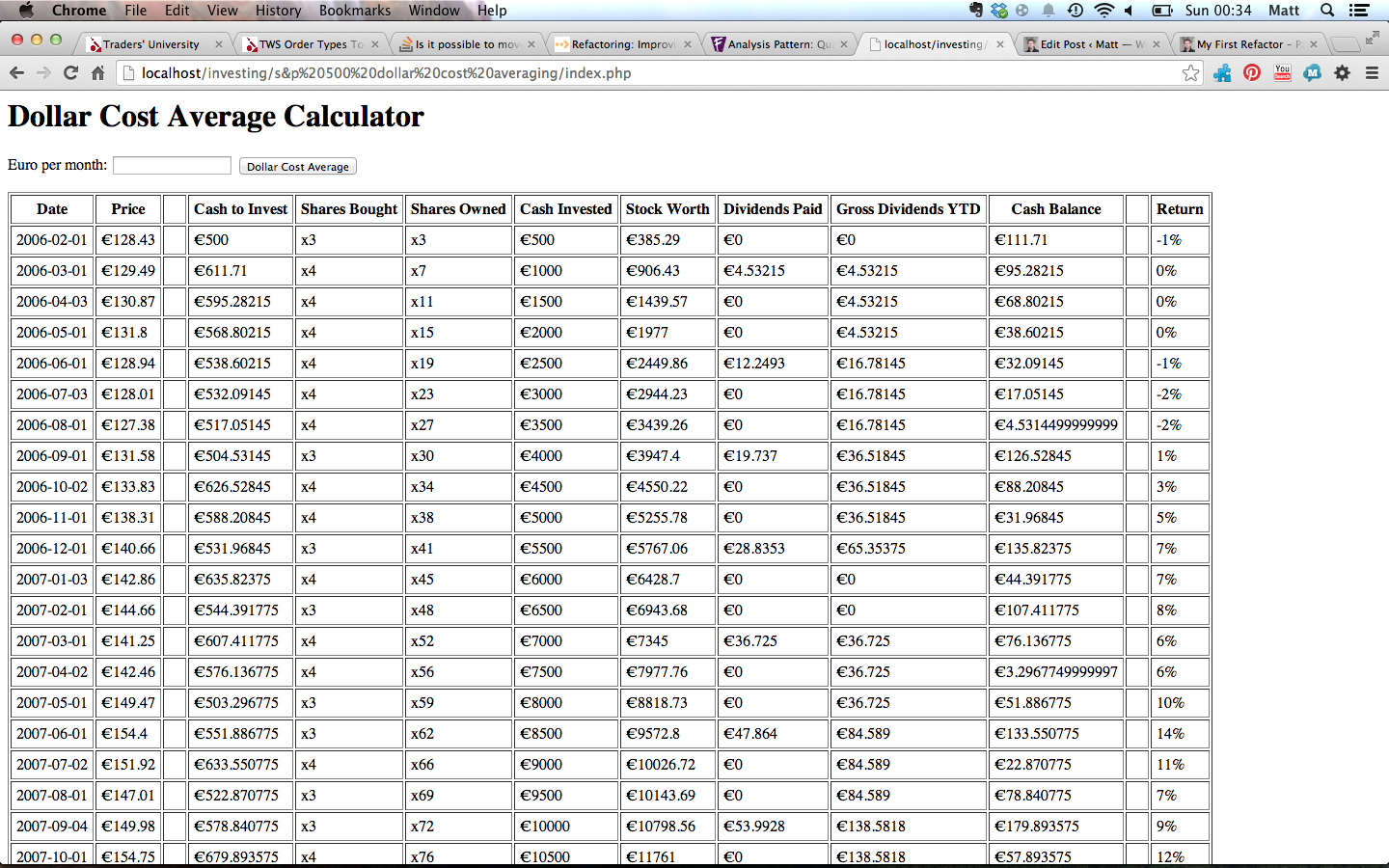
class DollarCostAverageStrategy
{
const DOLLAR_COST_PER_MONTH = 3;
const PERCENT_USA_DIVIDEND_WITHHOLDING_TAX = 0.15;
const PERCENT_IRISH_HIGHER_RATE_INCOME_TAX = 0.41;
const PERCENT_DIVIDEND_PER_QUARTER = 0.005;
const IRISH_TAX_PAYMENT_MONTH = 1;
function __construct($stock_prices) {
$this->stock_prices = $stock_prices;
}
function getInvestmentResults() {
while($row_data = $this->stock_prices->fetch_assoc())
$this->processStockPriceData($row_data);
return $this->investment_results;
}
private function processStockPriceData($row_data) {
if ($this->monthToInvestOn($row_data['date'])) {
$this->current_share_price = $row_data['high'];
if ($this->dayToInvestOn()) {
$this->calculateInvestmentResults($row_data['date']);
$this->incrementCurrentMonth();
}
}
}
private function monthToInvestOn($date_str) {
$date = DateTime::createFromFormat('Y-m-d', $date_str);
$month = $date->format('n');
return $month == $this->current_month;
}
private function dayToInvestOn() {
/// filter out 0 values
if ($this->current_share_price == 0)
return false;
if ($this->current_day < $this->day_of_month_to_buy_on) {
$this->current_day++;
return false;
}
return true;
}
private function calculateInvestmentResults($date) {
$this->transferMoneyToBroker();
$this->payBrokerCosts();
$this->buyMostSharesPossibleWithCashBalance();
$this->reinvestDividendsIfEarned();
$this->payIrishTaxes();
$this->storeThisMonthsInvestmentResults($date);
}
private function transferMoneyToBroker() {
$this->euro_invested += $this->euro_per_month;
$this->cash_balance += $this->euro_per_month;
$this->cash_at_start_of_month = $this->cash_balance;
}
private function payBrokerCosts() {
$this->cash_balance -= DollarCostAverageStrategy::DOLLAR_COST_PER_MONTH;
}
private function buyMostSharesPossibleWithCashBalance() {
$this->shares_purchased_in_current_month = intval($this->cash_balance / $this->current_share_price);
$this->shares_purchased += $this->shares_purchased_in_current_month;
$this->cash_balance -= $this->shares_purchased_in_current_month * $this->current_share_price;
}
private function reinvestDividendsIfEarned() {
$this->gross_dividends_this_year += $this->calculateDividendPayment();
$this->cash_balance += $this->calculateDividendPayment();
}
private function payIrishTaxes() {
if ($this->current_month == DollarCostAverageStrategy::IRISH_TAX_PAYMENT_MONTH) {
$tax_payable_to_revenue_on_us_dividends = $this->percentIrishTaxToPay() * $this->gross_dividends_this_year;
$this->cash_balance -= $tax_payable_to_revenue_on_us_dividends;
// reset dividend aggregate
$this->gross_dividends_this_year = 0;
}
}
private function storeThisMonthsInvestmentResults($date) {
$investment_result = array('date' => $date,
'share_price' => $this->current_share_price,
'cash_at_start_of_month' => $this->cash_at_start_of_month,
'num_shares_can_buy' => $this->shares_purchased_in_current_month,
'shares_purchased' => $this->shares_purchased,
'euro_invested' => $this->euro_invested,
'stock_worth' => $this->getStockWorth(),
'dividends_paid' => $this->calculateDividendPayment(),
'gross_dividends_this_year' => $this->gross_dividends_this_year,
'cash_balance' => $this->cash_balance,
'percentage_return' => intval(
($this->cash_balance+$this->getStockWorth())
* 100 / $this->euro_invested
) - 100);
array_push($this->investment_results, $investment_result);
}
private function calculateDividendPayment() {
$dividend_this_month = ($this->current_month == 3 or
$this->current_month == 6 or
$this->current_month == 9 or
$this->current_month == 12) ? 1 : 0;
return $this->shares_purchased
* $this->current_share_price
* DollarCostAverageStrategy::PERCENT_DIVIDEND_PER_QUARTER
* $dividend_this_month;
}
private function getStockWorth() {
return $this->shares_purchased * $this->current_share_price;
}
private function percentIrishTaxToPay() {
return DollarCostAverageStrategy::PERCENT_IRISH_HIGHER_RATE_INCOME_TAX
- DollarCostAverageStrategy::PERCENT_USA_DIVIDEND_WITHHOLDING_TAX;
}
private function incrementCurrentMonth() {
$this->current_month++;
if ($this->current_month == 13) {
$this->current_month = 1;
}
}
private $current_month = 2;
private $current_day = 1;
private $euro_invested;
private $cash_balance;
private $euro_per_month = 500;
private $shares_purchased = 0;
private $day_of_month_to_buy_on = 1;
private $gross_dividends_this_year = 0;
private $current_share_price;
private $cash_at_start_of_month;
private $shares_purchased_in_current_month;
private $investment_results = array();
}